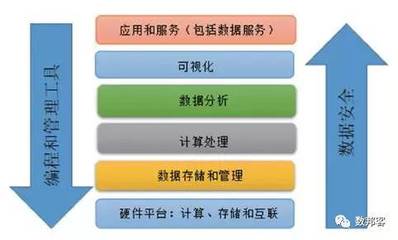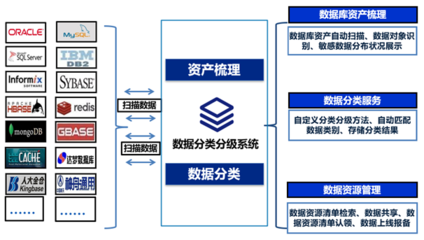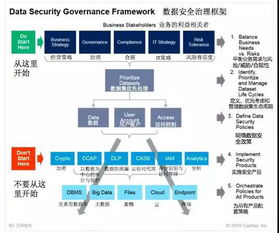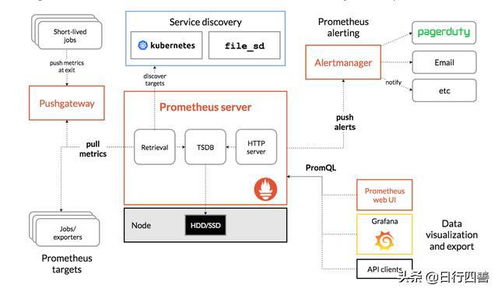
随着大数据和云计算的深度融合,数据湖已成为企业整合多源异构数据、支撑高级分析的关键架构。对象存储服务(如阿里云OSS)凭借其高扩展性、低成本和高可靠性,成为构建云上数据湖的热门存储底座。对象存储与传统的HDFS等文件系统在设计哲学上存在显著差异,如何面向OSS优化数据湖分析,以充分发挥其潜力并规避其局限,是当前数据架构师与工程师面临的核心课题。
一、对象存储(OSS)在数据湖中的优势与挑战
优势:
1. 无限扩展与成本效益:OSS提供近乎无限的存储空间,并采用按需付费模式,无需预先规划容量,存储成本显著低于传统块或文件存储。
2. 高耐久性与可用性:通过多副本或纠删码技术,保障数据的高持久性(通常高达11个9)和高可用性。
3. 协议兼容性与生态集成:支持S3等标准协议,能够与Spark、Presto、Flink等主流大数据计算引擎及各种数据湖格式(如Delta Lake、Apache Iceberg、Hudi)无缝集成。
挑战:
1. 最终一致性与列表操作延迟:部分OSS服务(尤其是分布式场景下的列表操作)可能存在最终一致性,可能导致短暂的数据可见性延迟,影响作业准确性。
2. 元数据操作性能:重命名、删除等操作可能非原子性或代价较高,这与基于目录的文件系统体验不同。
3. 无“文件锁”机制:不支持原生的并发写入锁,对需要ACID事务的数据湖格式提出了更高要求。
4. 网络开销与数据本地性缺失:计算与存储分离架构下,数据需通过网络访问,可能带来延迟和带宽成本。
二、数据处理优化策略
- 计算引擎深度调优:
- 分区与谓词下推:充分利用数据湖表格式的分区剪枝和统计信息(如min/max),在OSS层面过滤无关数据,减少I/O。
- 智能文件扫描:优化目录列表(LIST)操作,采用并行列表、缓存元数据(如使用Alluxio加速)或直接利用数据湖格式的元数据清单(如Iceberg的Manifest文件)来避免频繁的OSS列表调用。
- 并发度与连接优化:根据OSS的带宽和请求限制(QPS),合理调整计算任务的并发度、分片大小,并优化Join策略以减少数据混洗。
- 采用数据湖表格式:
- ACID事务与时间旅行:借助Delta Lake、Iceberg等格式,在OSS之上实现原子提交、并发控制、数据版本回溯,有效规避OSS无锁的缺陷。
- 高效的元数据管理:这些格式将元数据(如表结构、分区信息、文件列表)也存储在OSS中,但通过精心设计的清单文件和数据文件组织,使得元数据操作更高效,减少对OSS的直接列表依赖。
- 数据组织优化:支持小文件自动合并(Compaction)、数据聚类(Clustering/Z-Ordering),提升查询性能并降低存储成本。
- 缓存与加速层引入:
- 在计算集群与OSS之间部署分布式缓存系统(如Alluxio、JindoFS),将热数据缓存到本地SSD或内存中,提供内存级访问速度,并减轻OSS带宽压力。
- 对于迭代式机器学习或交互式查询场景,缓存层能带来显著的性能提升。
三、存储服务优化策略
- 数据生命周期与分层存储:
- 利用OSS提供的生命周期策略,自动将冷数据从标准存储类型转换到低频访问、归档或冷归档存储,大幅降低长期存储成本。
- 数据湖表格式的元数据文件(如Iceberg的元数据JSON、清单文件)应始终保留在标准或低频存储层,确保快速访问。
- 数据布局与分区设计:
- 遵循“分区适度”原则,避免创建过深或过多的分区(例如按小时分区可能导致海量小文件),这会加剧OSS列表操作负担。建议根据查询模式和数据量选择合适的分区粒度(如按天、按月)。
- 采用基于数据内容的聚类(如按用户ID、地理位置),使查询能更精准地定位到OSS上的文件块。
- 小文件治理:
- 小文件是数据湖在OSS上性能的“头号杀手”,会极大增加元数据开销和查询启动时间。通过流式写入的微批处理、定期的压缩(Compaction)作业,将小文件合并为大小合理(如128MB-1GB)的文件。
- 安全与访问优化:
- 利用OSS的STS临时令牌、服务端加密、客户端加密等功能保障数据安全。
- 优化网络路径,确保计算集群与OSS Bucket处于同一地域(Region),甚至同一可用区,并使用内网Endpoint访问,以降低延迟和公网带宽费用。
四、最佳实践与未来展望
构建以OSS为基的数据湖时,推荐采用 “数据湖表格式 + 计算引擎调优 + 智能缓存 + 生命周期管理” 的组合拳。例如,架构可以设计为:原始数据入湖后,通过Spark Structured Streaming写入Delta Lake/Iceberg表格式,存储在OSS上;利用Spark或Presto进行交互查询,并通过JindoFS进行缓存加速;配置OSS生命周期策略自动管理数据冷热。
随着OSS服务本身的演进(如提供更强的一致性保证、更快的元数据操作)以及与计算引擎、数据湖格式的更深度集成(如原生的向量化读取、索引支持),基于对象存储的数据湖分析性能与易用性将进一步提升,持续推动企业数据驱动决策的进程。
面向OSS优化数据湖分析是一个系统工程,需要从存储、数据组织、计算引擎多个层面协同考虑。通过理解和尊重对象存储的特性,并灵活运用现代数据湖技术栈,我们完全可以在享受其高扩展、低成本红利的构建出高性能、可靠的企业级数据分析平台。