一、Kafka架构概述与Controller选举机制
Apache Kafka是一个分布式流处理平台,其核心设计遵循高吞吐、可扩展和持久化的原则。Kafka集群由多个Broker组成,每个Broker可以处理数据的读写请求。其中,Controller是Kafka集群的“大脑”,负责管理分区和副本的状态。
Controller选举机制:
1. Kafka集群启动时,所有Broker都会尝试在ZooKeeper的/controller节点创建临时节点。
2. 第一个成功创建该节点的Broker成为Controller,其他Broker在该节点上注册Watcher监听。
3. 若Controller宕机,临时节点消失,其他Broker通过Watcher感知并重新触发选举。
4. 新Controller负责分区状态机管理、副本状态机管理及元数据同步。
二、Partition副本与Leader选举
Kafka通过副本机制保证数据可靠性。每个分区(Partition)有多个副本,分为Leader和Follower:
- Leader副本:处理所有读写请求。
- Follower副本:从Leader异步拉取数据,保持与Leader同步。
Leader选举触发条件:
1. 分区创建时。
2. Leader副本所在Broker宕机。
3. 分区进行重分配(如Rebalance)。
选举过程:
1. Controller监控分区状态,发现Leader失效后,从ISR(In-Sync Replicas,同步副本列表)中选择新Leader。
2. 选举原则:优先选择ISR中的第一个副本(可通过配置调整)。
3. 若ISR为空,根据unclean.leader.election.enable配置决定是否从非同步副本选举(可能丢失数据)。
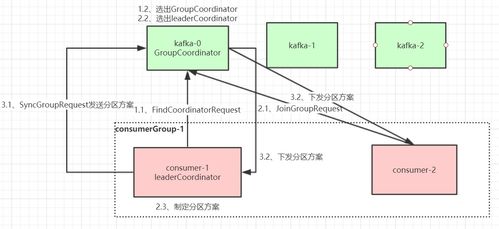
三、消费者Rebalance与分区分配策略
消费者组(Consumer Group)通过Rebalance实现负载均衡和容错。触发条件包括:消费者加入/离开、订阅主题分区数变化。
分区分配策略:
1. Range策略:按分区号顺序分配,可能导致分配不均。
2. RoundRobin策略:轮询分配,要求所有消费者订阅相同主题。
3. Sticky策略:尽量保留原有分配,减少分区迁移开销。
4. Cooperative Sticky策略:支持增量Rebalance,避免全局暂停。
Rebalance流程:
1. 消费者向Coordinator(一个Broker)发送JoinGroup请求。
2. Coordinator选举Group Leader(第一个加入的消费者)。
3. Group Leader执行分配算法,将结果同步给Coordinator。
4. Coordinator下发分配方案,消费者开始消费。
四、日志存储:HW、LEO与日志分段
Kafka的日志存储是高性能设计的核心:
HW与LEO:
- LEO(Log End Offset):分区副本最新消息的下一个位置。
- HW(High Watermark):ISR中所有副本均已同步的消息位置,消费者只能读到HW之前的数据。
- 更新机制:Follower从Leader拉取数据后更新LEO,Leader根据ISR副本同步情况更新HW。
日志分段存储(Log Segment):
1. 每个分区日志被切分为多个Segment文件,便于管理和清理。
2. 文件包括:.log(数据)、.index(偏移量索引)、.timeindex(时间戳索引)。
3. 滚动策略:基于时间(log.roll.hours)或大小(log.segment.bytes)。
4. 清理策略:基于时间(retention.ms)或大小(retention.bytes),支持删除和压缩。
五、ZooKeeper节点数据管理
Kafka依赖ZooKeeper存储元数据(新版本正逐步移除):
- Broker注册:
/brokers/ids/[brokerId]存储Broker地址、版本等信息。 - Topic配置:
/brokers/topics/[topic]存储分区副本分配方案。 - Controller选举:
/controller存储当前Controller信息。 - 消费者组:
/consumers/[groupId]记录消费者偏移量(旧版本)。 - 集群配置:
/config存储动态配置参数。
六、数据处理与存储服务
数据写入流程:
1. Producer发送消息到指定分区Leader副本。
2. Leader将消息追加到日志文件,更新LEO。
3. Follower拉取消息后,Leader更新HW并响应Producer。
数据读取流程:
1. Consumer从Leader副本拉取数据(只能消费HW之前的消息)。
2. 通过零拷贝(Zero-Copy)技术直接从页缓存传输数据,减少CPU开销。
3. 支持批量拉取和压缩传输。
存储优化特性:
1. 页缓存(Page Cache):利用操作系统缓存,避免直接磁盘读写。
2. 顺序写入:日志文件仅追加写入,大幅提升磁盘IO效率。
3. 索引机制:通过.index文件快速定位消息位置。
4. 压缩机制:支持GZIP、Snappy、LZ4等压缩算法,减少网络和存储开销。
##
Kafka的设计融合了分布式系统的经典思想:通过Controller集中管理元数据、副本机制保障可用性、消费者组实现负载均衡、日志分段和索引优化存储效率。理解这些原理有助于在实际应用中合理配置集群、优化性能并快速排查问题。随着Kafka演进,其架构正逐步减少对ZooKeeper的依赖(如KIP-500),向更自洽的方向发展。