在 MySQL 数据库中,InnoDB 存储引擎因其支持事务、行级锁、崩溃恢复和外键约束等关键特性,成为了最广泛使用的存储引擎。理解其数据存储结构,是深入掌握数据处理与存储服务如何高效、可靠工作的基石。本章将系统解析 InnoDB 的数据存储逻辑与物理结构。
一、核心存储单元:表空间与段
InnoDB 的所有数据都存储在表空间(Tablespace)中。表空间是 InnoDB 存储引擎逻辑结构的最高层,可以看作是一个或多个实际数据文件的逻辑集合。
- 系统表空间(ibdata1):默认情况下,InnoDB 的数据字典、双写缓冲区(Doublewrite Buffer)、更改缓冲区(Change Buffer)以及所有表和索引的数据都存储在此。通过配置
innodb<em>file</em>per_table参数,可以改为每个表使用独立的表空间文件(.ibd 文件)。 - 独立表空间(.ibd 文件):当启用
innodb<em>file</em>per_table后,每个 InnoDB 表的数据和索引会存储在单独的.ibd文件中。这带来了更好的管理灵活性,例如可以单独对某个表进行压缩或快速删除(DROP TABLE 操作会直接删除该文件,空间立即释放)。
表空间由多个段(Segment)组成。每个索引(无论是聚簇索引还是二级索引)都会分配两个段:叶子节点段(Leaf Segment) 和 非叶子节点段(Non-Leaf Segment)。段是 InnoDB 进行空间分配和管理的主要单位。
二、数据组织的基本单位:区与页
段由更小的单元——区(Extent)构成。每个区大小固定为 1MB(在默认页大小为 16KB 时,包含 64 个连续的页)。引入区的概念是为了提高空间分配效率和顺序 I/O 性能。当段开始增长时,InnoDB 不是一次分配一页,而是一次分配一个完整的区。
页(Page) 是 InnoDB 磁盘管理的最小单位,也是数据读写的基本单元。默认每个页的大小为 16KB(可通过 innodb<em>page</em>size 参数调整,但一旦数据库创建,通常无法更改)。所有数据(行记录、索引、系统信息)都存储在页中。
页有多种类型,其中最重要的是:
- 数据页(INDEX):存储行数据和 B+Tree 索引节点。
- Undo 页(UNDO_LOG):存储事务回滚所需的旧版本数据,是实现 MVCC(多版本并发控制)的关键。
- 系统页:如 FSPHDR, IBUFBITMAP 等,用于管理文件空间和变更缓冲区。
三、数据行的存储:行格式与页内结构
数据是如何在页内组织的呢?这取决于表的行格式(Row Format)。InnoDB 支持多种行格式,如 REDUNDANT, COMPACT, DYNAMIC(MySQL 5.7 默认), COMPRESSED。以默认的 DYNAMIC 格式为例:
- 行记录结构:每条记录除了用户定义的数据列外,还包含一些系统字段:
- 事务ID(DBTRXID):6字节,记录最近修改该行的事务ID。
- 回滚指针(DBROLLPTR):7字节,指向 Undo Log 中旧版本数据的指针,用于实现 MVCC 和事务回滚。
- 行ID(DBROWID):6字节,如果表未定义主键,InnoDB 会自动生成一个隐藏的聚簇索引(基于此列)。
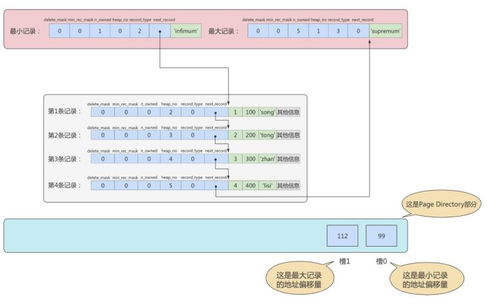
- 页内布局:一个数据页通常包含:
- File Header / Page Header:记录页的元信息,如页号、前后页指针(构成双向链表)、页类型等。
- Infimum + Supremum Records:两个虚拟的系统行记录,分别表示页中最小和最大的记录,用于界定边界。
- User Records:实际存储的用户行记录,按照主键顺序以单向链表的形式组织。
- Free Space:页中尚未使用的空间。
- Page Directory:页目录,对页内的用户记录进行稀疏索引(槽 Slot),用于加速页内记录的查找(二分查找)。
- File Trailer:用于校验页数据的完整性。
四、索引组织表:B+Tree 结构
InnoDB 采用 索引组织表(Index-Organized Table) 的存储方式。这意味着表数据本身(所有用户列)就存储在聚簇索引(Clustered Index)的叶子节点中。
- 聚簇索引:通常就是主键索引。如果没有显式定义主键,InnoDB 会选择一个唯一的非空索引代替,如果也没有,则会隐式创建一个包含
DB<em>ROW</em>ID的聚簇索引。数据行物理上按照聚簇索引键值的顺序存储。 - 二级索引(Secondary Index):叶子节点存储的不是完整的数据行,而是该索引的键值加上对应的聚簇索引键值。通过二级索引查找数据时,需要先查到主键值,再“回表”到聚簇索引中查找完整行记录。
InnoDB 的 B+Tree 索引具有以下特点:
- 所有叶子节点都在同一层,并通过双向链表连接,便于范围扫描。
- 非叶子节点仅存储索引键值和指向子节点的指针。
- 这种结构使得基于主键的等值查询和范围查询效率极高。
五、数据处理与存储服务的协同
理解了存储结构,就能看清数据处理服务(SQL 引擎、事务管理器)与底层存储服务的协同:
- 数据读取:查询优化器选择索引后,存储引擎从根页开始,在 B+Tree 中导航,定位到目标页,利用页目录快速找到行记录。如果涉及二级索引,则需“回表”。
- 数据写入/修改:
- 数据首先被写入缓冲池(Buffer Pool) 中的页(内存中页的副本)。
- 修改会生成 Redo Log(重做日志,物理日志,顺序写)保证持久性,和 Undo Log(回滚日志,逻辑日志)保证原子性与 MVCC。
- 脏页由后台线程根据一定策略(Checkpoint)刷新回磁盘表空间文件。
- 事务与并发控制:借助行中的
DB<em>TRX</em>ID和DB<em>ROLL</em>PTR,结合 Undo Log 链,为不同事务提供数据行的多版本视图(MVCC),从而实现非锁定读和高并发。行级锁也是直接加在索引记录上的。 - 崩溃恢复:数据库重启时,通过比较数据页和 Redo Log,可以重做已提交但未刷盘的事务,并利用 Undo Log 回滚未提交的事务,从而保证数据的一致性状态。
###
InnoDB 的数据存储结构是一个从宏观表空间到微观行记录、层次分明、紧密协作的精巧体系。它以页为基本 I/O 单元,以 B+Tree 索引组织数据,通过日志先行(WAL)和多版本控制等机制,在磁盘这一相对慢速的介质上,构建了一个高效、可靠的数据处理与存储服务。深入理解这一结构,对于进行数据库性能调优、故障排查和架构设计至关重要。