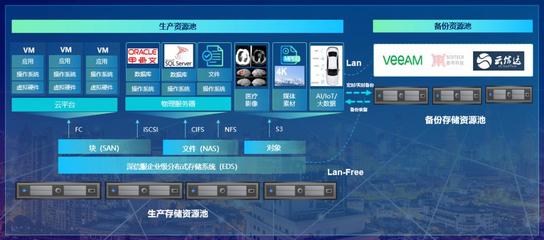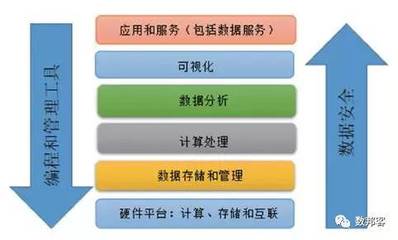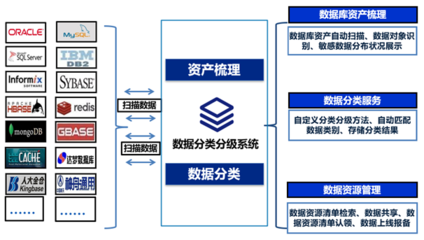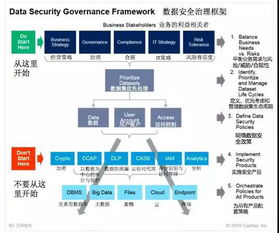
数据结构是计算机科学中组织和存储数据的核心理论与方法,是构建高效数据处理与存储服务的基石。无论是传统数据库,还是现代云计算、大数据平台,其底层都依赖于精心设计的数据结构。理解并掌握数据结构,如同掌握了构建高效、可靠数字服务的“内功心法”。
一、数据结构:数据处理服务的效率引擎
数据处理服务的核心任务是高效地进行数据的增、删、改、查。不同的数据结构为此提供了不同的性能特征:
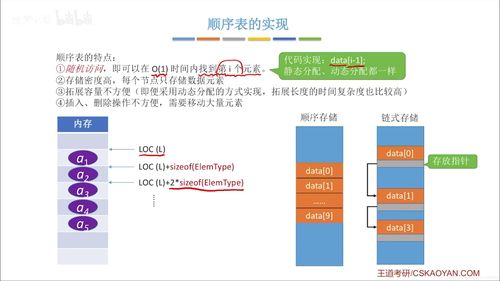
- 线性结构(如数组、链表):是数据存储的基本单元。数组支持随机访问,适合频繁查找;链表支持高效插入删除,是动态数据集合的基础。
- 树形结构(如二叉树、B树、B+树):是数据库索引的支柱。B+树因其平衡性和顺序访问特性,被广泛应用于关系型数据库(如MySQL)的索引实现中,极大加速了范围查询和数据检索。
- 哈希结构:通过哈希函数将键直接映射到存储位置,提供近乎O(1)时间复杂度的查找,是缓存系统(如Redis)、键值存储和快速去重的核心。
二、数据结构:存储服务的组织蓝图
数据如何持久化存储并快速定位,直接决定了存储服务的性能与可靠性。
- 文件与磁盘管理:操作系统中的文件系统(如EXT4, NTFS)使用索引节点(inode)等数据结构来管理磁盘块,记录文件元数据和物理位置。
- 数据库存储引擎:现代数据库的存储引擎(如InnoDB)将表数据以B+树索引的形式组织在页(Page)中,页是磁盘与内存交互的基本单位。这种结构保证了数据在磁盘上的有序性,优化了I/O效率。
- 分布式存储:在大数据与云存储场景中,如Google的Bigtable、Apache HBase,使用类似“排序字符串表”(SSTable)的结构存储数据,并结合布隆过滤器(Bloom Filter)等概率数据结构快速判断数据是否存在,减少不必要的磁盘访问。
三、王道实践:从理论到服务架构
掌握数据结构的“王道”,在于深刻理解其时空复杂度,并能根据服务需求进行选型和组合。
- 设计缓存服务:结合哈希表(快速查找)与双向链表(实现LRU淘汰策略),可以构建一个高效的LRU缓存。
- 设计实时排行榜:使用跳表(Skip List)或平衡树(如红黑树),可以在动态数据流中高效维护有序集合并支持快速排名查询。
- 保障服务高可用:在分布式系统中,一致性哈希数据结构能有效解决节点扩容缩容时的数据重新分配问题,最小化数据迁移量,提升服务的稳定性和可扩展性。
###
数据结构并非抽象的理论,而是贯穿于每一个数据处理与存储服务背后的设计灵魂。从内存中的高速计算到磁盘上的持久化组织,再到分布式环境下的协同管理,优秀的数据结构选择与实现是服务达到高性能、高可靠、高可扩展目标的根本保障。深入理解数据结构,就是握住了开启高效数字世界大门的钥匙。