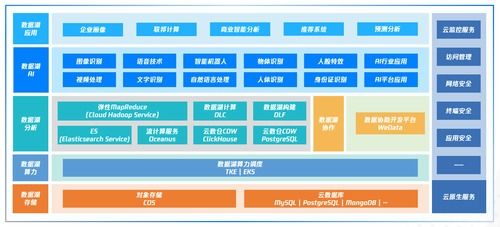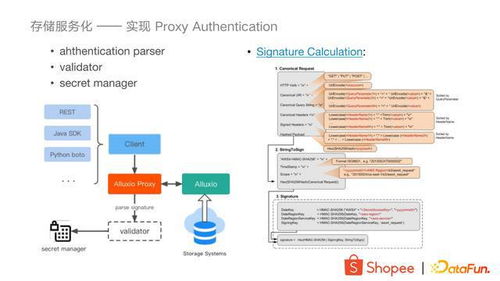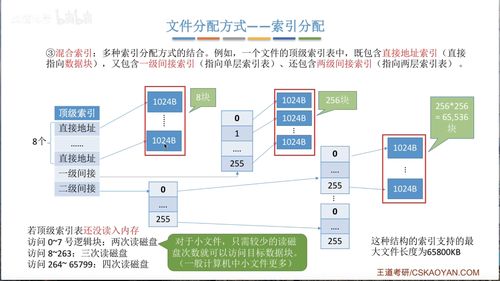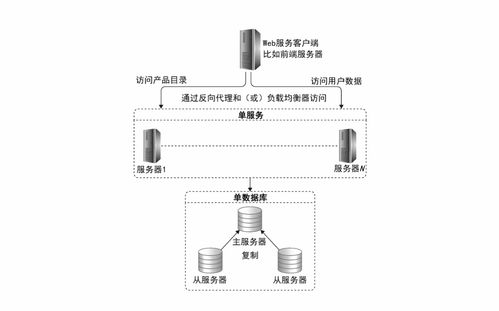
在分布式系统架构中,数据存储作为基石,其设计与实现直接决定了系统的扩展性、可靠性与性能。本章节将深入探讨分布式数据存储的核心技术,特别是数据处理与存储服务在现代架构中的关键作用与实践原则。
一、分布式数据存储的核心挑战与设计目标
分布式数据存储旨在解决单机存储的容量、性能与可用性瓶颈,其核心设计目标包括:高可用性(通过冗余实现故障容错)、可扩展性(支持水平扩容)、一致性(在分布式环境中维护数据正确性)以及高性能(低延迟与高吞吐)。这些目标往往相互制约,架构师需根据业务场景权衡取舍,例如在CAP定理的框架下选择合适的一致性模型。
二、数据处理服务:从批处理到实时流式处理
数据处理服务负责对存储的数据进行加工、分析与转换,通常分为两类:
- 批处理:适用于离线分析场景,如Hadoop、Spark等框架,通过分布式计算处理海量历史数据,优势在于吞吐量大,但延迟较高。
- 流式处理:满足实时性需求,如Apache Flink、Kafka Streams,可对数据流进行连续处理,实现低延迟的实时洞察。架构师需根据业务对时效性的要求,设计混合处理管道,例如Lambda架构或Kappa架构。
三、存储服务选型:数据库与存储系统的多样性
分布式存储服务根据数据模型与访问模式可分为多种类型:
- 关系型数据库(分布式):如Google Spanner、TiDB,提供ACID事务与SQL接口,适合强一致性要求的场景,但扩展复杂度较高。
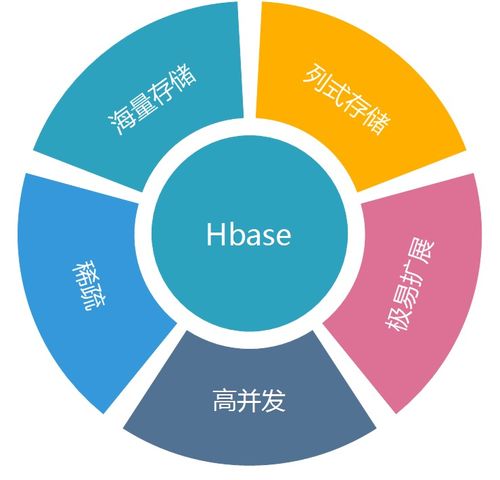
- NoSQL数据库:包括键值存储(如Redis、DynamoDB)、文档存储(如MongoDB)、列族存储(如HBase)等,强调水平扩展与灵活模式,但可能牺牲一致性或功能完整性。
- 对象存储:如Amazon S3、Ceph,适用于非结构化数据(如图片、视频),提供高耐久性与低成本存储。
- 时序数据库与图数据库:针对特定场景优化,如InfluxDB处理时间序列数据,Neo4j处理关联关系。
四、核心技术实践:分片、复制与一致性协议
实现分布式存储依赖以下核心技术:
- 数据分片(Sharding):将数据水平分割到多个节点,以分散负载与存储压力。分片策略(如范围分片、哈希分片)需考虑数据均衡与查询效率。
- 数据复制(Replication):通过多副本提升可用性与读性能,但引入一致性问题。常用复制模型包括主从复制、多主复制与无主复制(如Dynamo风格)。
- 一致性协议:如Paxos、Raft用于保证副本间的一致性;分布式事务协议(如两阶段提交)则用于跨分片操作。在实践中,架构师常采用最终一致性或读写仲裁(Quorum)来平衡性能与一致性。
五、现代架构趋势:云原生与存算分离
随着云计算的普及,分布式数据存储呈现新趋势:
- 云原生存储服务:托管服务(如AWS Aurora、Azure Cosmos DB)简化了运维,提供自动扩缩容与全局分布式能力。
- 存算分离架构:将存储与计算资源解耦,通过高速网络(如RDMA)连接,实现独立扩展与成本优化,常见于数据湖与大数据平台。
- 多模数据库与统一查询层:为简化架构,支持多种数据模型的数据库(如Azure Cosmos DB)或通过统一查询引擎(如Presto、Apache Iceberg)访问异构存储逐渐流行。
六、架构师修炼要点
- 场景驱动选型:避免技术堆砌,根据数据特征(结构化程度、访问模式)、业务需求(一致性、延迟要求)及团队能力选择存储方案。
- 设计容错与监控:分布式系统故障是常态,需实现自动故障转移、数据备份与实时监控(如延迟、错误率指标)。
- 关注数据安全与合规:加密传输与静态数据、访问控制及数据生命周期管理不可或缺。
- 成本优化:权衡存储成本(如SSD与HDD)、网络开销及运维复杂度,采用分层存储与数据压缩等策略。
分布式数据存储不仅是技术组件的组合,更是业务逻辑与系统约束的平衡艺术。架构师需持续追踪技术演进,如新兴的Serverless数据库与边缘存储,同时在实践中积累故障处理经验,方能构建稳健高效的数据基石。